
By Michael Every of Rabobank
Expect much self-serving market chuckling about ‘TACO Tuesday’ again as Monday’s US-China trade talks in London extend into today and headlines are that the US may loosen its export controls on some goods if China releases its on rare earths.
Is that really a TACO though? These were unilateral US moves against China taken after the recent Geneva agreement, so dropping them this only takes us back to where we were weeks ago, and presumably for the clear deliverable of getting rare earths flowing again as the US had expected…. until the US has them flowing from elsewhere, that is. A true TACO --Truly Appalling ‘Clever’ Option’-- would be the White House not doing the latter because economists tell them that “because markets” local rare earth processing is more expensive.
As evidence of a distinct lack of poultry, which coincidentally came up in a conversation yesterday, in WW1, the British found they were reliant on Germany for optical glass needed for binoculars, while Germany was short of the rubber it had sourced from the British Empire. Both decided to swap these strategic goods with each other via Switzerland (though this is disputed by some).
Interestingly, the Chinese press report of these talks state “The US...trade deficit in goods with China is not only the inevitable result of the structural problems of the US economy but also determined by the comparative advantages of the two countries." Who knew neo-mercantilist Chinese economists were the same Ricardian neoliberals as at western universities and institutions? Of course, they aren’t - but they know writing it wins over those who dine on TACOs.
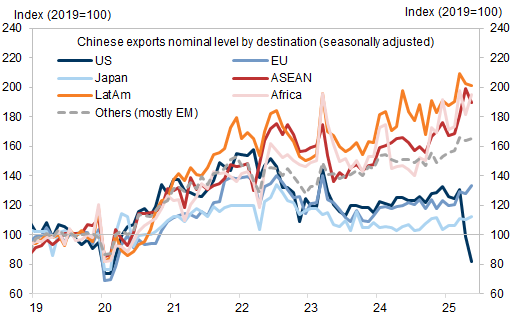
And chew on May’s Chinese trade data: exports to the US -34.5%; to the EU +12%; to Germany +21.5%; to France +24.1%; and to Netherlands +7.1%. This isn’t a US-China problem and those that taco that approach will deindustrialise.
Meanwhile, it’s unclear how much chickening out there is in geopolitics. Ukrainian drones just hit another Russian military target, destroying two fighter jets, as Germany’s outgoing spy boss and NATO chief Rutte both warned Russia could launch an attack against it within five years. “Let’s not kid ourselves, we are all on the eastern flank. There is no east or west, there is just NATO,” Mr Rutte said, and the danger “will not disappear when the war in Ukraine ends.”
Rutte specifically told the UK: “Spend more or learn to speak Russian.” To help Brits appalled at the idea of learning a foreign language, and those who believe it might be better than vast state spending when fiscal deficits and public debt are sky high: “Когда мне снизят центральную банковскую процентную ставку?” (‘When do I get my rate cut?’ – that’s all that matters, right?)
Even Canada is moving its Coast Guard to national defence and PM Carney will announce defence spending will be NATO’s 2% of GDP target this fiscal year - just in time for it to rise to 5% at its upcoming summit.
Of course, Europe is just one front. Iran will reportedly reject the proposed US nuclear deal and offer its own that allows it nuclear enrichment and demands the “forced” destruction of Israel’s nuclear arsenal, according to the New York Times. Israeli PM Netanyahu rushed from a court appearance to speak to Trump about it, where he was told the US sees Iran and Gaza as linked and wants deals “so there’s no destruction and death.” Expect more US-Iran talks this weekend. However, that’s as Iran's top security body says the intel it just obtained about Israel’s nuclear facilities mean it could launch counterattacks should Israel strike its.
And if that isn’t enough, India is ready to strike ‘deep into Pakistan’ if provoked, New Delhi just warned.
Meanwhile, President Trump sent 700 marines to LA on top of the National Guard to try to restore order following riots at the enforcement of the deportation of illegal immigrants, upping the political ante, as Governor Newsom sued to have this reversed. As the New York Times claims ‘The US is no longer a stable country’, recall this is the same US that has seen past presidential assassinations, with two attempts against Trump in 2024; this long list of riots; that past White Houses have sent in federal forces to restore order at the state level; and, for ‘doomers’, that the refusal of states to accede to federal authority was related to the US Civil War.
This matters for markets, and not just because the US is already hardly looking the safe-haven it once did. Logically, if Trump’s LA action fails, a template may be set that while the US border is now closed, mass deportations de facto cannot happen, implying the current default for labor markets. However, if Trump succeeds, it suggests he may be able to press ahead like past presidents (Reagan removed 8 million people, and Clinton and George W. Bush 10 million each), with very different labor market implications. Moreover, success would boost Trump’s standing; and failure would both weaken it and imply a de facto one-way turnstile border with longer-term socio-economic implications and politically polarizing effects. Similar issues are of course being seen in many western democracies at the moment.
On which note, French President Macron refused to rule out new legislative elections as soon as next month, though his last try at that backfired on him, seeing gains for the far right and left vs. his centrists.
Very much in the 2025 spirit, a report also claims the Pentagon has been faking UFO sightings to keep people unaware of their own breakthroughs. I have a friend who would immediately respond: “That’s what they want you to think.” Yet at the same time, Axios says the ‘scariest reality’ is that the firms eagerly building AI don’t know how or why it works but are sitting back and watching it let rip. I would say that as new graduates already find entry-level jobs are being replaced by AI that potential mass unemployment ahead is a pretty scary thought too.
Lastly, in markets, China is to deepen its use of a $1.5 trillion state housing fund to offer cheaper mortgages than its state-owned banks can. That’s certainly a new wrinkle on ‘what is GDP for?’ and does suggest some fine-tuning of the economy.
You put all this together and it’s really hard to make a convincing case that we are seeing any real ‘chickening out’. Chicken Littles or headless chickens, possibly. Truly Appalling ‘Clever’ Options, certainly.

{kind=link}